層次:RNN、FC 和 LogSoftmax。
透過整合神經網路層次,我們能夠提取更抽象的特徵,有助於區分或 分類範例。 然而,當涉及具有因果關係或嵌套嵌入的時序序列時,MLP 和 CNN 往往束手無策,通常需要大量的神經元或核函數,才能捕捉看似合乎邏輯的推理,從而接近表象之下蘊藏的真相。
為說明傳統神經網路的局限性,我們將採用兩種不同方法——MLP與簡單的 RNN——來處理一個小型任務。 假設我們正在模擬兩個 3 位數十進制數的加法運算,模型面臨的挑戰在於釐清我們自訂資料集背後隱含的進位機制。 我們之所以能輕鬆計算加法,是因為我們被教導要處理從低位數到高位數的進位,且必須依序進行。 讓我們開始看看,一個淺層的簡單 RNN 是否真的能模擬加法運算。
加法專用自訂資料集
| # | 特徵 | 標籤 |
|---|---|---|
| 1 | [[8, 0], [3, 4], [4, 5]] | [8, 7, 9] |
| 2 | [[3, 3], [3, 5], [0, 4]] | [6, 8, 4] |
| 3 | [[5, 7], [5, 9], [9, 3]] | [2, 5, 3] |
此資料集是透過 0 到 9 之間整數的均勻分佈,逐位元隨機生成的。 上表分別顯示了資料集的前三個範例,包含輸入特徵與標籤。 每個範例中,有三組整數對,分別代表由左至右的個位、十位和百位數字。 換言之,第一組三位數是 (438, 540),其和應為 978。 此排列方式與小端序 (LE) 相似,惟基數為十進位。
單一範例的形狀為 $(\textbf{timeSeq}, \textbf{featureSize})$,此結構模擬了人類心智的算術運算,可直接餵入 RNN。 然而,多層迴路神經網路(MLP)無法處理 $\textbf{timeSeq}$ 維度,因此我們將所有範例重塑為 $(\textbf{timeSeq} \times \textbf{featureSize})$ 的形狀。 資料集包含 1,000 個範例,我們將其分為三部分(50%, 10%, 40%)分別用於訓練、驗證和測試。
模型:MLP 對比 簡易 RNN
除了普通的 MLP 之外,我們用來處理三位數加法問題的循環模型是 Elman 網路的一種實例。 Elman 網路僅有一個由簡易循環神經元組成的循環層。 簡易循環神經元是一個普通的神經元,就像全連接層中的神經元一樣,再加上一個有向的自我迴路。
由於網路的能力與其可學習參數的數量密切相關,因此模型規模的上限設定為 800 個參數。 我們設計了一個結構為 20-30 的 2 層精簡多層感知器 (MLP),以及一個由單層簡單 RNN 隱藏層(含 21 個神經元)和輸出層的線性層(含 10 個神經元)組成的簡單 RNN。 MLP 和 RNN 的參數總數分別為 770 和 745。
MLP 模型定義
|
|
(Python 程式碼的顯示僅在深色模式下正確。我稍後會修正淺色模式。)
簡單 RNN 模型定義
|
|
加法模擬任務的兩個模型定義如上所示的兩個 PyTorch 模組。 我們盡可能讓兩個模型的定義保持相似,以便讀者進行比較並聚焦於兩者之間的差異。 在每個模型的末端,我們使用對數軟最大似然層來計算對數 odds,以配合負對數似然損失函數。 讀者應已理解對數 odds 比層與損失函數的選用依據。 值得注意的是,RNN 模型多了一個名為 ${\bf initRNNState}$ 的成員函數,用於初始化隱藏狀態。此步驟至關重要,因為隱藏狀態會透過指向每個隱藏循環神經元自身的權重,參與計算該神經元的輸出以及下一個隱藏狀態。 隱藏狀態的維度形狀為 $(\textbf{batchSize}, \textbf{rnnLayers}, \textbf{hiddenSize})$,其中 $\textbf{rnnLayers}$ 為 RNN 層數,而 $\textbf{hiddenSize}$ 為迴圈神經元的數量。 在 3 位數加法任務的 RNN 模型中,我們將 $\textbf{rnnLayer}$ 設為 1。
訓練框架
|
|
網路訓練框架的三大關鍵部分如上方的 Python 程式碼所示。 ${\bf predict}$ 函式接受形狀為 $(\textbf{batchSize}, \textbf{timeSeq}, \textbf{featureSize})$ 的 CUDA FloatTensor 作為輸入,並返回形狀為 $(\textbf{batchSize}, \textbf{timeSeq})$、類別範圍為 $\in \left [0, 9 \right ]$ 的整數預測結果。 ${\bf testAcc}$ 函式透過後處理封裝預測函式,以計算驗證/測試準確度。 訓練的主體包含一個兩層嵌套迴圈。 外層迴圈遍歷所有 epoch,並定期驗證模型。 內層迴圈將每個小批次資料餵入網路模型,執行反向傳播以計算梯度,並在優化器中更新可訓練參數。 此框架可應用於兩種模型的訓練流程。
| |
|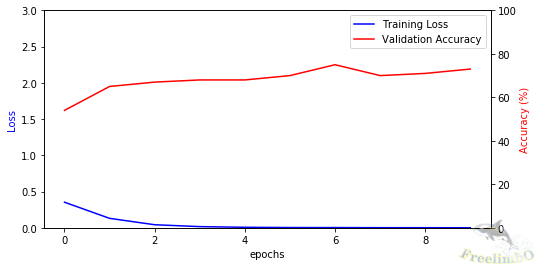
| 圖 1. MLP 的學習曲線。 | 圖 2. 簡單 RNN 的學習曲線 |
我們將學習率設定為 0.0001,並總共進行 20,000 個 epoch(當任一模型的損失降至 0.001 以下時即停止)。 在優化器方面,我們選擇 Adam,因為它在不增加過多運算開銷的情況下,通常能比 SGD 表現更佳。 MLP 和 RNN 的學習曲線分別如圖 1 和圖 2 所示。 顯然,擁有 770 個可訓練參數的 MLP 無法學習 3 位數加法,而擁有 745 個可訓練參數的 RNN 則成功完成了這項任務。 這兩種模型的測試準確度分別為:MLP 為 0.25%,RNN 為 76.25%。
結果與討論
| # | 測試特徵 | MLP 預測 | RNN 預測 | 正確加法 |
|---|---|---|---|---|
| 1 | [[4, 5], [3, 3], [3, 1]] | [[6, 4, 2] | [9, 6, 4] | 334 + 135 = 469 |
| 2 | [[4, 7], [8, 9], [3, 2]] | [[0, 7, 5] | [1, 7, 6] | 384 + 297 = 671 |
| 3 | [[8, 8], [0, 4], [0, 7]] | [[5, 8, 0] | [6, 5, 7] | 8 + 748 = 756 |
| 4 | [[3, 8], [1, 8], [3, 4]] | [[9, 1, 0] | [1, 0, 8] | 313 + 488 = 801 |
| 5 | [[6, 1], [2, 9], [2, 5]] | [[7, 8, 5] | [7, 0, 8] | 226 + 591 = 807 |
| 6 | [[4, 5], [3, 8], [3, 1]] | [[0, 9, 5] | [9, 1, 5] | 334 + 185 = 519 |
多層迴路神經網路(MLP)的失敗與反向迴路神經網路(RNN)的成功,實則是一枚硬幣的兩面:額外的進位正是時間資訊的體現。 MLP 會同時接收例子的所有輸入特徵,但僅能提取空間特徵。 然而,RNN 具備自迴路機制,能將先前激活狀態回傳至當前運算中,這使得模型能夠理解時間資訊。 上表列出了這兩種已訓練模型在小端序模式下的部分測試樣本。 第一個範例是將 334 與 135 相加,正確的和應為 469。 MLP 輸出錯誤的 246,而 RNN 則給出了正確答案。 我們可以仔細檢視以下五個範例,發現 RNN 雖然仍會出錯,但它已經理解到,先前一對操作數的加法必定產生進位,且該進位需要加到當前的加法運算中。 至於多層迴路神經網路(MLP)模型,即使在單位位元(與最左側輸入對相關的位元)上,我們也幾乎看不到任何正確或接近正確的預測結果,而該位元本就不存在需要擔心的進位問題。
|
|---|
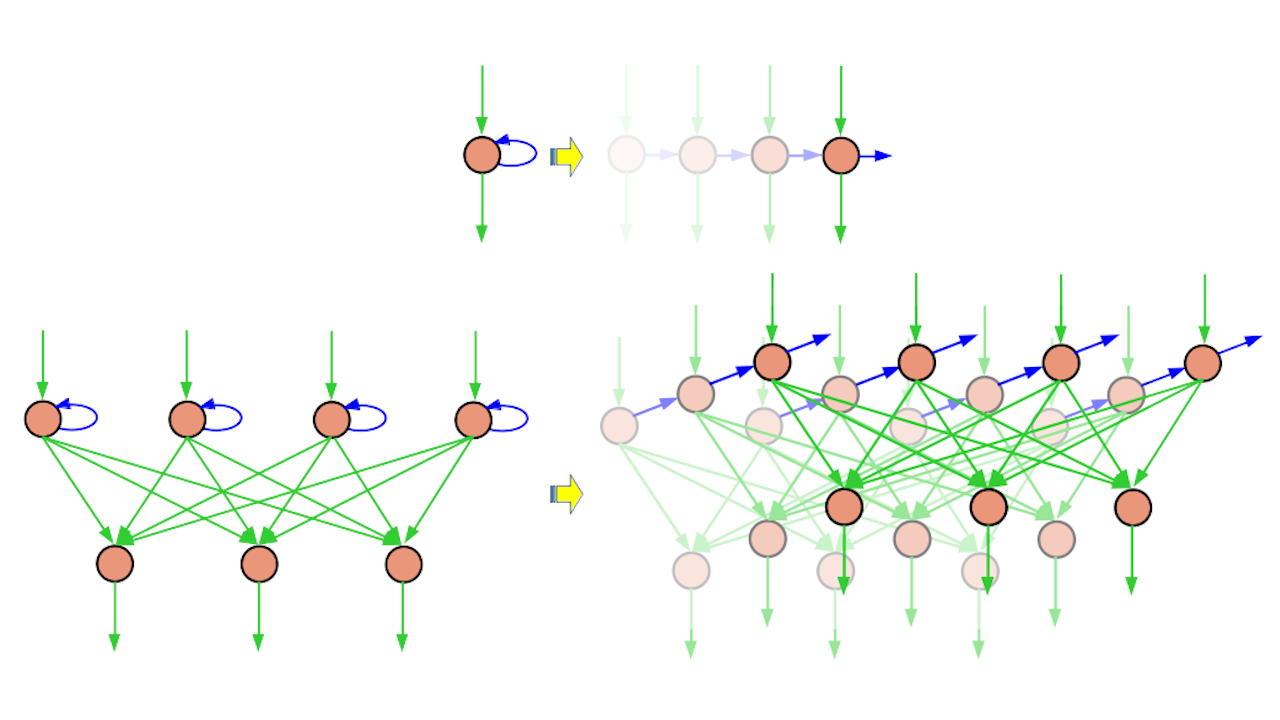
| 簡單 RNN 神經元與 Elman 網路的展開圖 |
最後但同樣重要的是,封面圖片展示了 Elman 網路沿時間軸展開的樣貌。展開後的藍色箭頭將成為通往同一層更高克隆(時間上較後)的連接;因此,進位資訊得以找到路徑,進而影響鄰近的位數。